분할 정복
작성날짜 2022/04/09
분할 정복
분할 정복의 핵심 개념은 큰 규모의 문제를 작은 문제로 나누어 해결하는 방식이다.
- 분할(divide): 주어진 문제를 동일한 방식으로 해결할 수 있는 여러 부분 문제로 나눈다.
- 정복(conquer): 각 부분 문제에 대한 해답을 구한다.
- 결합(combine): 각 부분 문제의 해답을 결합하여 전체 문제에 대한 해답을 구한다.
분할 정복을 이용한 정렬 알고리즘
정렬 알고리즘의 필요한 요구 사항
- 모든 데이터 타입에 대해 동작하야여 한다. 정수, 실수 등의 자료형에 모두 사용할 수 있어야 한다. 이는 C++ 구조체와 클래스에 대해서도 마찬가지다.
- 정렬 알고리즘은 많은 양의 데이터를 처리할 수 있어야 한다. 즉, 컴퓨터의 메인 메모리보다 큰 용량의 데이터에 대해서도 동작해야 한다.
- 정렬 알고리즘은 점근적 시간 복잡도 측면이나 실제 동작 시에 빠르게 동작해야 한다.
분할 정복을 이용한 정렬 알고리즘 2가지
- 병합 정렬(merge sort) 1940년대 컴퓨터의 적은 메인 메모리 -> 이를 해결하기 위해 전체 집합을 작은 크기의 부분 집합으로 나누어 정렬하고, 정렬된 부분 집합을 오름차순 또는 내림차순 순서를 유지하면서 합치는 방식
- 퀵 정렬(quick sort)은 평균 실행 시간을 줄이는 것이 목표. 입력 배열이 주어지고 입력 배열 중 피벗(pivot) 원소 P를 선택했을 경우, 퀵 정렬을 위한 분할 연산은 다음 두 단계로 이루어짐
퀵 정렬
퀵 정렬을 위한 분할 연산
- 입력 배열을 두개의 부분 배열 L과 R로 나눈다. LF은 입력 배열에서 P보다 작거나 같은 원소를 포함하는 부분 배열이고, R은 입력 배열에서 P보다 큰 원소를 포함하는 부분 배열이다.
- 입력 배열을 L, P, R 순서로 재구성한다.
분할 연산 전
| 5(피벗) | 8 | 6 | 1 | 4 | 3 | 7 | 9 | 2 |
분할 연산 후
| 1(L) | 4(L) | 3(L) | 2(L) | 5(피벗) | 8(R) | 6(R) | 7(R) | 9(R) |
전체적인 퀵 정렬 알고리즘
- 입력 배열 A가 두 개 이상의 원소를 가지고 있다면 A에 분할 연산을 수행한다. 그러면 부분 배열 L과 R이 생성된다.
- 1단계의 입력으로 L을 사용한다.(재귀적)
- 1단계의 입력으로 R을 사용한다.(재귀적)
| 유용한 STL 알고리즘 함수 | |
| STL 함수 | 함수 설명 |
| std::binary_search() | 이진 검색을 이용하여 컨테이너에서 원소 하나를 찾는다. |
| std::search() | 컴테이너에서 일련의 원소들을 찾는다. |
| std::upper_bound() | 컨테이너에서 주어진 값보다 큰 원소가 나타나기 시작하는 위치의 반복자를 반환한다. |
| std::lower_bound() | 컨테이너에서 주어진 값보다 작은 원소가 나타나기 시작하는 위치의 반복자를 반환한다. |
| std::partition() | 분할 연산을 수행하고, 주어진 피벗보다 작은 원소는 피벗 왼쪽으로 옮기고 피벗보다 큰 원소는 피벗 오른쪽으로 옮긴다. |
| std::partition_copy() | 분할 연산을 수행하고, 그 결과를 별도의 두 배열로 반환한다. |
| std::is_partitioned() | 주어진 피벗을 기준으로 분할이 되어 있는지를 검사한다. |
| std::stable_partition() | 분할 연산을 수행하며, 각 파티션 원소는 원본 순서를 유지한다. |
| std::sort() | 컨테이너 원소를 정렬한다. 내부적으로 여러 정렬 알고리즘을 조합하여 사용한다. |
| std::stable_sort() | 컨테이너 원소를 정렬하되, 서로 순위가 같은 원소에 대해 원본 순서가 변경되지 않도록 정렬한다. |
| std:;partial_sort() | 컨테이너 전체가 아니라 일부 구간에 대해서 정렬한다. |
| std::merge() | 두 개의 입력 컨테이너를 합친다. 이때 두 컨테이너의 원소 순서는 그대로 유지된다. |
| std::nth_element() | 컨테이너에서 n번째로 작은 원소를 반환한다. |
| std::accumulate() | 컨테이너 원소릐 누적 합을 계산한다. 이 함수는 다른 외부 함수를 지정하여 누적 합이 아닌 다른 연산을 수행할 수도 있다. |
| std::transform() | 컨테이너와 함수가 주어지면, 컨테이너의 모든 원소에 대해 해당 함수를 적용하여 값을 수정한다. |
| std::reduce() | 지정한 범위의 원소에 대해 리듀스 연산을 수행하고 결과를 반환한다. |
맵리듀스(mapreduce)
맵리듀스를 처음 소개한 논문-
"맵리듀스는 대규모 데이터셋을 생성하고 처리하기 위한 프로그래밍 모델 및 구현입니다. 사용자는 키와 값의 쌍르 처리하여 중간 단계의 키/값 쌍을 생성하는 맵(map) 함수와 같은 중간 단계 키에 해당하는 모든 중간 단계 값을 병합하는 리듀스(reduce) 함수를 지정합니다."
맵리듀스 프로그래밍 모델에 대한 여러 오픈 소스 구현 코드가 있으며 그중 대표적인 것이 하둠(Hadoop).
맵리듀스의 추상화
맵은 컨테이너 C를 입력받아, 컨테이너의 모든 원소에 함수 f(x)를 적용하는 연산.
리듀스는 컨테이너 C의 모든 원소 x에 함수 f(acc, x)를 적용하여 하나의 값으로 축약하는 연산.
아래 코드는 std의 transform과 reduce를 사용하는 예제이다.
#include <iostream>
#include <vector>
#include <algorithm>
#include <numeric>
#include <cmath>
// 맵 연산 테이스 함수 작성 f(x) =x*x 함수를 사용하여
// 인자로 넘어온 벡터의 모든 원소를 제곱한다.
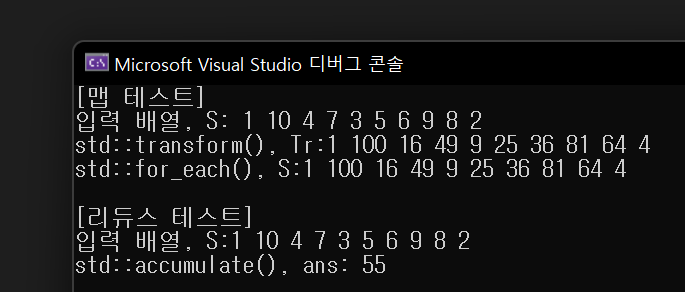
void transform_test(std::vector<int> S) {
std::vector<int> Tr;
std::cout << "[맵 테스트]" << std::endl;
std::cout << "입력 배열, S: ";
for (auto i : S)
std::cout << i << " ";
std::cout << std::endl;
//std::transform() 함수 사용
std::transform(S.begin(), S.end(), std::back_inserter(Tr), [](int x) {return std::pow(x, 2.0); });
std::cout << "std::transform(), Tr:";
for (auto i : Tr)
std::cout << i << " ";
std::cout << std::endl;
//std::for_each() 함수 사용
std::for_each(S.begin(), S.end(), [](int& x) {x = std::pow(x, 2.0); });
std::cout << "std::for_each(), S:";
for (auto i : S)
std::cout << i << " ";
std::cout << std::endl;
}
void redece_test(std::vector<int> S) {
std::cout << std::endl << "[리듀스 테스트]" << std::endl;
std::cout << "입력 배열, S:";
for (auto i : S)
std::cout << i << " ";
std::cout << std::endl;
//std::accumulate() 함수 사용
auto ans = std::accumulate(S.begin(), S.end(), 0, [](int acc, int x) {return acc + x; });
std::cout << "std::accumulate(), ans: " << ans << std::endl;
}
int main()
{
std::vector<int> S{ 1, 10, 4, 7, 3, 5, 6, 9, 8, 2 };
transform_test(S);
redece_test(S);
}실행결과: